一、Graph CNN [2016]
《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》
卷积神经网络提供了一种有效的架构,可以在大规模的、高维的数据集中抽取非常有意义的统计模式(
statistical pattern)。CNN学习局部静态结构(local stationary structure)并将它们组合成多尺度的(multi-scale)、分层(hierarchical)的模式,并导致了图像识别、视频识别、声音识别等任务的突破。准确地说,CNN通过揭示跨数据域(data domain)共享的局部特征来抽取输入数据(或输入信号)的局部平稳性(local stationarity)。这些相似的特征通过从数据中学到的局部卷积滤波器(localized convolutional filter)(或局部卷积核localized convolutional kernel)来识别。卷积滤波器是平移不变(translation-invariant)的,这意味着它们能够独立于空间位置来识别相同的特征(identical feature)。局部核(localized kernel) (或紧凑支持的滤波器compactly supported filter)指的是独立于输入数据大小并抽取局部特征的滤波器,它的支持度(support)大小可以远小于输入大小。社交网络上的用户数据、电信网络上的日志数据、或
word embedding上的文本文档,它们都是不规则数据的重要例子,这些数据可以用图 (graph) 来构造。图是异质pairwise关系的通用表达(universal representation)。图可以编码复杂的几何结构,并且可以使用强大的数学工具进行研究,如谱图理论(spectral graph theory)。将
CNN推广到图并不简单,因为卷积算子和池化算子仅针对规则网格(regular grid)才有定义。这使得CNN的扩展在理论上和实现上都具有挑战性。将CNN推广到图的主要瓶颈(也是论文《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》的主要目标之一),是定义可以有效评估和学习的局部图滤波器localized graph filter。准确地说,论文《Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering》的主要贡献如下:谱公式 (
spectral formulation):基于图信号处理(graph signal processing: GSP)中已有的工具,论文建立了图上CNN的谱图(spectral graph)理论公式。严格局部的滤波器:可以证明,论文提出的谱滤波器(
spectral filter)严格限定在半径为K hops。这是对《Spectral Networks and Deep Locally Connected Networks on Graphs》的增强。低的计算复杂度:论文提出的滤波器的
evaluation复杂度与滤波器尺寸degree。这使得计算复杂度与输入数据大小此外,论文的方法完全避免了傅里叶基(
Fourier basis),因此避免了计算傅里叶基所需要的特征分解 (eigenvalue decomposition)所需的计算量,也避免了存储傅里叶基的内存需求(一个GPU内存有限时尤其重要。除了输入数据之外,论文的方法只需要存储拉普拉斯算子,它是一个包含高效的池化:论文提出了一种有效的、图上的池化策略,该策略在将顶点重排为二叉树结构之后,采用类似于一维信号的池化。
实验结果:论文进行了多个实验,最终表明所提出的公式是:一个有效的模型、计算效率高、在准确性和复杂性上都优于
《Spectral Networks and Deep Locally Connected Networks on Graphs》中介绍的spectral graph CNN。论文还表明,所提出的图公式在
MNIST上的表现与经典CNN相似,并研究了各种图构造(graph construction)对于性能的影响。
相关工作:
图信号处理(
graph signal processing: GSP):GSP的新兴领域旨在弥合信号处理和谱图理论之间的gap,是图论(graph theory)和谐波分析(harmonic analysis)之间的融合。一个目标是将信号的基本分析操作从规则网格推广到不规则的图结构。诸如卷积、平移、滤波 (filtering)、膨胀 (dilatation)、调制 (modulation)、降采样(downsampling)等等网格上的标准操作不会直接扩展到图,因此需要新的数学定义,同时保持原有的直观概念。在这种情况下,已有工作重新审视了图上小波算子(wavelet operator)的构建,并提出了在图上执行mutli-scale pyramid transform。也有一些工作重新定义了图上的不确定性原理,并表明虽然可能会丢失直观的概念,但是可以导出增强的局部性准则 (localization principle)。非欧几里得(
Non-Euclidean)域的CNN:图神经网络框架《The Graph Neural Network Model》(在《Gated Graph Sequence Neural Networks》中被简化)旨在通过RNN将每个节点嵌入到一个欧氏空间,并将这些embedding用作节点/图的分类/回归的特征。一些工作引入了构建局部感受野(
local receptive field)的概念从而减少学习参数的数量。这个想法是基于相似性度量将特征组合在一起,例如在两个连续层之间选择有限数量的连接。虽然该模型利用局部性假设(locality assumption)减少了参数的数量,但是它并没有尝试利用任何平稳性,即没有权重共享策略。《Spectral Networks and Deep Locally Connected Networks on Graphs》的作者在他们的graph CNN的spatial formulation中使用了这个想法。他们使用加权图来定义局部邻域,并为池化操作计算图的多尺度聚类(multiscale clustering)。然而,在空域构造(spatial construction)中引入权重共享具有挑战性,因为当缺少problem-specific ordering(如空间顺序、时间顺序等等)时,它需要选择(select)并对邻域内的节点进行排序。《Geodesic convolutional neural networks on riemannian manifolds》中提出了CNN到3D-mesh的空间推广,其中3D-mesh是一类平滑的、低维的非欧氏空间。作者使用测地线极坐标(geodesic polar coordinate)来定义mesh patch上的卷积,并定制了一个深度学习架构从而允许在不同的流形(manifold)之间进行比较。他们对3D形状识别获得了SOTA结果。第一个谱公式由
《Spectral Networks and Deep Locally Connected Networks on Graphs》提出,它将滤波器定义为:control point)向量。他们后来提出了一种从数据中学习图结构的策略,并将该模型应用于图像识别、文本分类、生物信息学(《Deep Convolutional Networks on Graph-Structured Data》)。然而,由于需要乘以图傅里叶基scale。此外,由于它们依赖于傅里叶域中的平滑性(smoothness)(即,通过样条参数化得到)来实现空间域的局部性,因此他们的模型无法提供精确的控制从而使得kernel支持局部性,而这对于学习局部的滤波器至关重要。我们的技术利用了这项工作,并展示了如何克服这些限制以及其它限制。
1.1 模型
将卷积推广到图上需要考虑三个问题:如何在图上设计满足空域局部性的卷积核、如何执行图的粗化(
graph coarsening)(即,将相似顶点聚合在一起)、如何执行图池化操作。
1.1.1 快速的局部性的谱滤波器
定义卷积滤波器有两种策略,可以从空间方法(
spatial approach)来定义,也可以从谱方法(spectral approach)来定义。通过构造(
construction),空间方法可以通过有限大小的kernel提供filter localization。然而,从空间角度来看,图上的平移没有唯一的数学定义。另一方面,谱方法通过在谱域(
spectral domain)实现的Kronecker delta卷积在图上提供了一个定义明确的局部性算子(localization operator)。然而,在谱域定义的滤波器不是天然局部化的,并且由于和图傅里叶基乘法的计算复杂度为然而,通过对滤波器参数化(
filter parametrization)的特殊选择,我们可以克服这两个限制(即,滤波器的天然局部化,以及计算复杂度)。
图傅里叶变换(
Graph Fourier Transform):给定无向图spectral graph analysis)中最基础的算子是图拉普拉斯算子,combinatorial Laplacian定义为normalized Laplacian定义为degree矩阵(一个对角矩阵)并且论文并没有提到是用哪个拉普拉斯矩阵,读者猜测用的是任意一个都可以,因为后续公式推导对两种类型的拉普拉斯矩阵都成立。
由于
graph Fourier mode),以及与这些特征向量相关的有序实数非负特征值graph frequency)。图拉普拉斯矩阵Fourier basis傅里叶变换将信号
filtering。图信号的谱域滤波(
spectral filtering):由于我们无法在顶点域(vertex domain)中表达有意义的平移算子(translation operator),因此图上的卷积算子Fourier domain),即:其中:
Hadamard乘法,因此,图上的信号
non-parametric filter(即参数都是自由的滤波器)定义为:其中参数
Fourier coefficient组成的向量。用于局部滤波器(
localized filter)的多项式参数化:然而,non-parametric filter有两个限制:它们在空间域不是局部化(localized)的、它们学习的复杂度是polynomial filter)来解决:其中:参数
以顶点
它的物理意义是:一个
delta脉冲信号根据
《Wavelets on Graphs via Spectral Graph Theory》的引理5.2,spectral filter)恰好是K-localized的。此外,它的学习复杂度为CNN的复杂度相同。快速滤波(
fast filtering)的递归公式:虽然我们已经展示了如何学习具有localized filter,但是由于还需要与傅里叶基一种这样的多项式是
Chebyshev展开(传统上,它在GSP中被用于近似kernel,如小波wagelet)。另一种选择是Lanczos算法,它构造了Krylov子空间的正交基Lanczos算法看起来似乎有吸引力,但是它更加复杂,因此我们留待未来的工作。回想一下,
这些多项式构成
其中:
参数
[-1,+1]之间。
滤波操作可以协作:
其中:
定义
整个滤波操作
学习
filter:假设第feature map) 。 第feature map为:其中:
layer的待训练参数。总的参数规模为假设
mini-batch样本的损失函数为其中:
mini-batch size。上述三种计算中的每一种都归结为
最后,
1.1.2 图粗化 Graph Coarsening
池化操作需要在图上有意义的邻域上进行,从而将相似的顶点聚类在一起。对多个
layer执行池化等价于保留局部几何结构的图多尺度聚类(multi-scale clustering)。然而,众所周知,图聚类 (graph clustering)是NP-hard的并且必须使用近似算法。虽然存在许多聚类算法(例如流行的谱聚类spectral clustering),但是我们最感兴趣的还是multi-level聚类算法。在multi-level聚类算法中,每个level都会生成一个更粗(coarser)的图,其中这个图对应于不同分辨率看到的数据域(data domain)。此外,在每个level将图的大小减少两倍的聚类技术提供了对粗化(coarsening)和池化大小的精确控制。在这项工作中,我们利用了
Graclus multi-level聚类算法的粗化阶段。Graclus multi-level聚类算法已被证明在对各种图进行聚类时非常有效。图上的代数多重网格(algebraic multigrid)技术、以及Kron reduction是未来工作中值得探索的两种方法。建立在
Metis上的Graclus使用贪心算法来计算给定图的连续更粗(successive coarser)的版本,并且能够最小化几个流行的谱聚类目标(spectral clustering objective)。在这些谱聚类目标中,我们选择归一化割(the normalized cut)。Graclus的贪心规则为:在每个
coarsening level,选择一个未标记(unmarked)的顶点local normalized cut然后标记(
mark)并粗化(coarsen)这对匹配的顶点持续配对,直到所有顶点都被探索(这样就完成了一轮粗化)。
这其中可能存在部分独立顶点,它不和任何其它顶点配对。
这种粗化算法非常块,并且每轮粗化都将顶点数除以
2从而从一个level到下一个更粗的level。
1.1.3 图信号的快速池化
池化操作将被执行很多次,因此该操作必须高效。粗化之后,输入图的顶点及其粗化版本没有以任何有意义的方式排列(
arrange) 。因此,直接应用池化操作将需要一个table来存储上一个level的顶点与到下一个level的顶点(更粗化的版本)之间的对应关系。这将导致内存效率低下、读取速度慢、并且难以并行化。然而,我们可以排列顶点,使得图池化(
graph pooling)操作变得与一维池化一样高效。我们分为两步进行:创建一棵平衡的二叉树、重排顶点。粗化之后,每个节点要么有两个子节点(如果它是在更精细的
level被匹配到的);要么没有(如果它在更精细的level未被匹配到),此时该节点是一个singleton,它只有一个子节点。从最粗的level到最细的level,我们为每个singleton节点添加一个fake节点作为子节点,这样每个节点就都有两个子节点。fake节点都是断开(disconnected)的。这种结构是一棵平衡二叉树:一个节点要么包含两个常规子节点(如下图中的
level 1节点0),要么包含一个singletons子节点和一个fake子节点(如下图中的level 2节点0) 。fake节点总是包含两个fake子节点,如下图中的level 1节点1。注意,下图中从上到下依次是level 0, level 1, level 2。输入信号在
fake节点处使用neutral value初始化,如当使用ReLU激活函数时为0。因为这些fake节点是断开的,因此滤波不会影响到初始的neutral value。虽然这些fake节点确实人为地增加了维度从而增加了计算成本,但是我们发现在实践中,Graclus留下的singleton节点数量非常少。我们在最粗(
coarsest)的level上任意排列节点,然后将这个次序传播到最精细(finest)的level,即节点level产生规则的次序(regular ordering)。规则的意思是相邻节点在较粗的level上层次地合并。池化如此一个重排的图信号,类似于池化一个常规的一维信号(以步长为2)。下图显示了整个池化过程的示例。这种规则排列 (
regular arrangement) 使得池化操作非常高效,并且满足并行架构(如GPU),因为内存访问是局部的,即不需要fetch被匹配的节点。池化的本质是:对每个节点多大范围内的邻域进行池化。
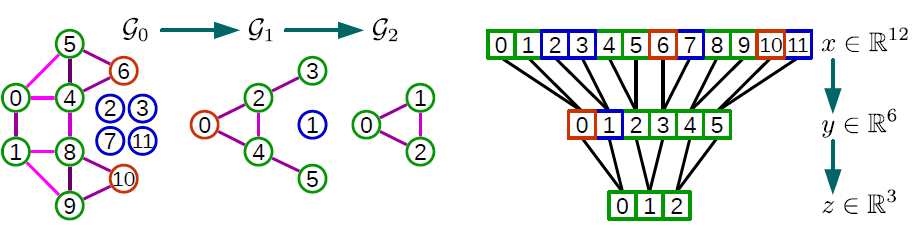
一个池化的例子如下图。带颜色的链接表示配对,红色圆圈表示未能配对顶点,蓝色圆圈表示
fake顶点。考虑图
4。level,它拥有4的池化,我们需要执行2次粗化操作(因为每次粗化都将顶点数除以2):Graclus第一次粗化产生图Graclus第二次粗化产生图level。
因此我们设置
fake节点(蓝色)添加到1个fake节点)、4个fake节点),从而与singelton节点(橙色)配对,这样每个节点正好有两个子节点。然后其中信号分量
neutral value。
1.2 实验
我们将
non-parametric和non-localized的filter称作Non-Param(即《Spectral Networks and Deep Locally Connected Networks on Graphs》中提出的filter称作Spline(即filter称作Chebyshev(即我们总是采用
Graclus粗化算法,而不是《Spectral Networks and Deep Locally Connected Networks on Graphs》中提出的简单聚集算法(agglomerative method)。我们的动机是比较学到的filter,而不是比较粗化算法。我们在描述网络架构时使用以下符号:
FCk表示一个带Pk表示一个尺寸和步长为GCK表示一个输出feature map的图卷积层(graph convolutional layer),Ck表示一个输出feature map的经典卷积层。所有的
FCk,GCk,Ck都使用ReLU激活函数。最后一层始终是softmax回归。损失函数FCk层权重的l2正则化。mini-batch sizeMNIST实验:我们考虑将我们的方法应用于基准的MNIST分类数据集,它是欧氏空间的case。MNIST分类数据集包含70000张数字图片,每张图片是28 x 28的2D网格。对于我们的图模型,我们构建了一个2D网格对应的8层图神经网络,它产生了192个fake节点),以及k-NN similarity graph的权重(即人工构建的input graph中,每条边的权重)计算为:其中
2D坐标。模型配置为(来自于
TensorFlow MNIST tutorial):LeNet-5-like的网络架构,并且超参数为:dropout rate = 0.5,正则化系数为0.03,学习率衰减系数0.95,动量0.9。标准卷积核的尺度为5x5,图卷积核的20个epoch。本实验是我们模型的一项重要的健全性检查 (
sanity check),它必须能够在任何图上抽取特征,包括常规的2D grid。下表显示了我们的模型与具有相同架构的经典CNN模型的性能非常接近。性能的差距可以用谱域滤波器的各向同性的特性(
isotropic nature)来解释,即常规graph中的边不具有方向性,但是MNIST图片作为2D grid具有方向性(如像素点的上下左右)。这是优势还是劣势取决于具体的问题。性能差距的其它解释是:我们的模型缺乏架构设计经验,以及需要研究更合适的优化策略或初始化策略。

20NEWS数据集的文本分类:为了验证我们的模型可应用于非结构化数据,我们将我们的技术应用于20NEWS数据集上的文本分类问题。20NEWS数据集包含18846篇文档,分为20个类别。我们将其中的11314篇文档用于训练、7532篇文档用于测试。我们从所有文档的93953个单词中保留最高频的一万个单词。每篇文档使用词袋模型(bag-of-word model) 提取特征,并根据文档内单词的词频进行归一化。为了测试我们的模型,我们构建了
16层图神经网络,图的构建方式为:其中
word2vec embedding。每篇文档对应一张图,它包含word2vec embedding是在当前数据集上训练的?还是在更大的、额外的数据集上训练的?论文未说明。所有模型都由
Adam优化器训练20个epoch,初始学习率为0.001。该架构是GC32。结果如下图所示,在这个小数据集上,虽然我们的模型未能超越Multinomial Naive Bayes模型,但是它超越了所有全连接神经网络模型,而这些全连接神经网络模型具有更多的参数。
效果比较:我们在
MNIST数据集上比较了不同的图卷积神经网络架构的效果,其中Spline以及需要Non-Param。
为了给出不同
filter的收敛性,下图给出训练过程中这几种架构的验证集准确率、训练集损失,横轴表示迭代次数。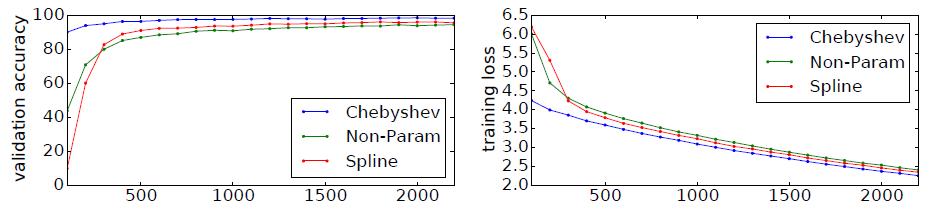
效率比较:我们在
20NEWS数据集上比较了不同网络架构的计算效率,其中《Spectral Networks and Deep Locally Connected Networks on Graphs》的计算复杂度为step数(即每个mini-batch的处理时间,其中batch-size = 100)。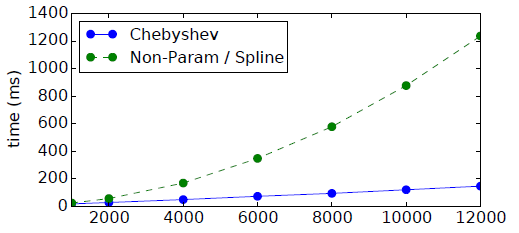
我们在
MNIST数据集上验证了不同网络架构的并行性。下表显式了从CPU迁移到GPU时,我们的方法与经典CNN类似的加速比。这体现了我们的模型提供的并行化机会。我们的模型仅依赖于矩阵乘法,而矩阵乘法可以通过NVIDA的cuBLAS库高效的支持。
图质量的影响:要使任何
graph CNN成功,数据集必须满足一定条件:图数据必须满足局部性(locality)、平稳性(stationarity)、组合性(compositionality)的统计假设。因此,学到的滤波器的质量及其分类性能关键取决于图的质量。从MNIST实验我们可以看到:从欧式空间的网格数据中基于kNN构建的图,这些图数据质量很高。我们基于这些图数据采用graph CNN几乎获得标准CNN的性能。并且我们发现,kNN中k的值对于图数据的质量影响不大。作为对比,我们从
MNIST中构建随机图,其中顶点之间的边是随机的。可以看到在随机图上,图卷积神经网络的准确率下降。在随机图中,数据结构发生丢失,因此卷积层提取的特征不再有意义。但是为什么丢失了结构信息之后,准确率还是那么高?读者猜测是有一些非结构性的因素在生效,例如某些像素点级别的特性。

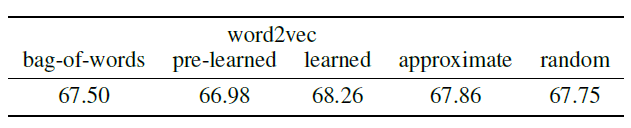
图像可以通过网格图来构成,但是必须人工地为
bag-of-word表示的文档来构建feature graph。我们在这里研究三种表示单词one-hot向量、通过word2vec从数据集中学习每个单词的embedding向量、使用预训练的单词word2vec embedding向量。对于较大的数据集,可能需要approximate nearest neighbor: ANN算法(因为当图的顶点数量较大时找出每个顶点的kNN顶点的计算复杂度太大),这就是我们在学到的word2vec embedding上尝试LSHForest的原因。下表报告了分类结果,这突出了结构良好的图的重要性。其中:bag-of-words表示one-hot方法,pre-learned表示预训练的embedding向量,learned表示从数据集训练embedding向量,approximate表示对learned得到的embedding向量进行最近邻搜索时使用LSHForest近似算法,random表示对learned得到的embedding向量采用随机生成边而不是基于kNN生成边。